2025
Embedding Safety into RL: A New Take on Trust Region Methods
Nikola Milosevic, Johannes Müller, Nico Scherf
International Conference on Machine Learning (ICML) 2025
Reinforcement Learning (RL) agents can solve diverse tasks but often exhibit unsafe behavior. Constrained Markov Decision Processes (CMDPs) address this by enforcing safety constraints, yet existing methods either sacrifice reward maximization or allow unsafe training. We introduce Constrained Trust Region Policy Optimization (C-TRPO), which reshapes the policy space geometry to ensure trust regions contain only safe policies, guaranteeing constraint satisfaction throughout training. We analyze its theoretical properties and connections to TRPO, Natural Policy Gradient (NPG), and Constrained Policy Optimization (CPO). Experiments show that C-TRPO reduces constraint violations while maintaining competitive returns.
Embedding Safety into RL: A New Take on Trust Region Methods
Nikola Milosevic, Johannes Müller, Nico Scherf
International Conference on Machine Learning (ICML) 2025
Reinforcement Learning (RL) agents can solve diverse tasks but often exhibit unsafe behavior. Constrained Markov Decision Processes (CMDPs) address this by enforcing safety constraints, yet existing methods either sacrifice reward maximization or allow unsafe training. We introduce Constrained Trust Region Policy Optimization (C-TRPO), which reshapes the policy space geometry to ensure trust regions contain only safe policies, guaranteeing constraint satisfaction throughout training. We analyze its theoretical properties and connections to TRPO, Natural Policy Gradient (NPG), and Constrained Policy Optimization (CPO). Experiments show that C-TRPO reduces constraint violations while maintaining competitive returns.
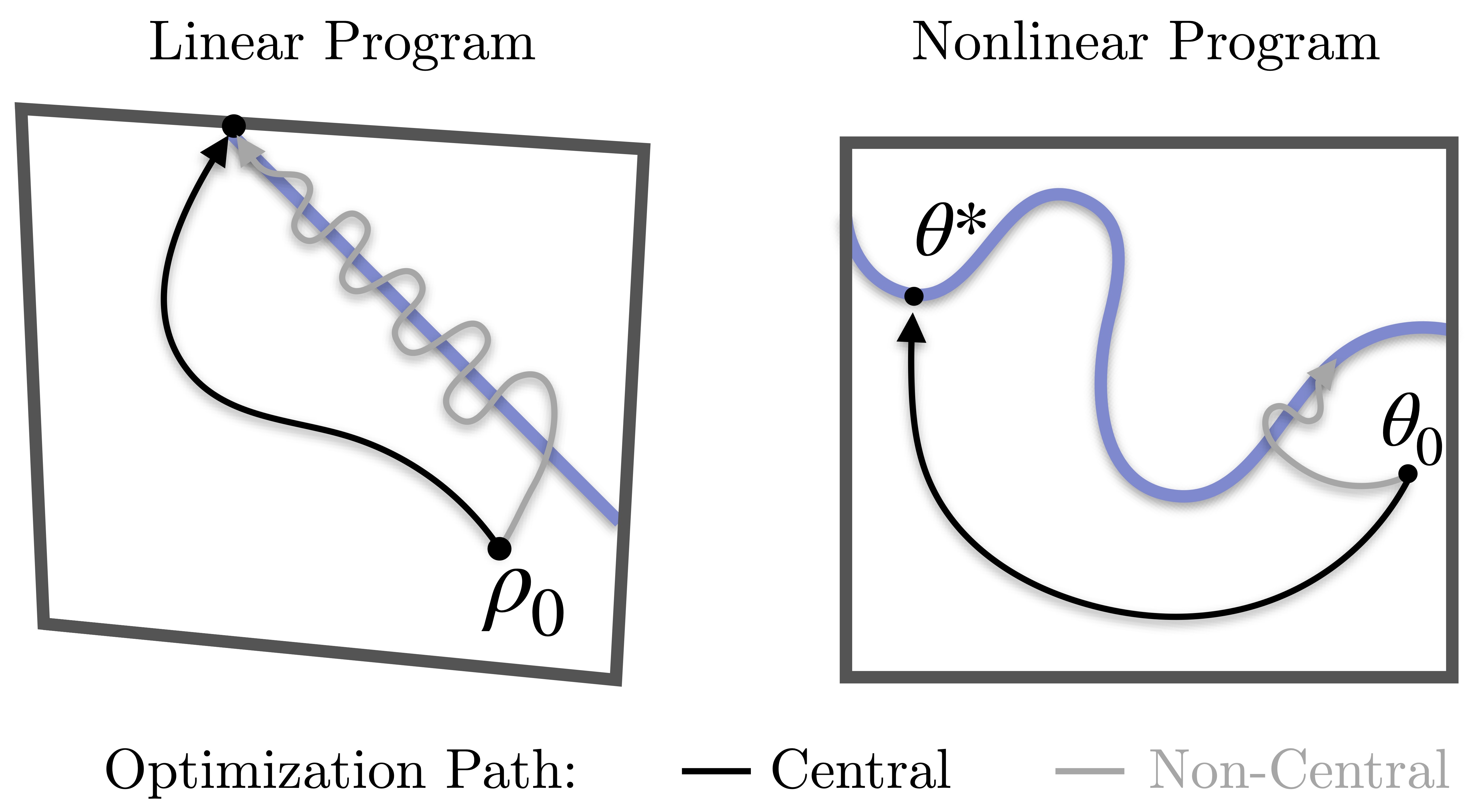
Central Path Proximal Policy Optimization
Nikola Milosevic, Johannes Müller, Nico Scherf
The Exploration in AI Today Workshop at ICML 2025 2025
In constrained Markov decision processes, enforcing constraints during training is often thought of as decreasing the final return. Recently, it was shown that constraints can be incorporated directly in the policy geometry, yielding an optimization trajectory close to the central path of a barrier method, which does not compromise final return. Building on this idea, we introduce Central Path Proximal Policy Optimization (C3PO), a simple modification of PPO that produces policy iterates, which stay close to the central path of the constrained optimization problem. Compared to existing on-policy methods, C3PO delivers improved performance with tighter constraint enforcement, suggesting that central path-guided updates offer a promising direction for constrained policy optimization.
Central Path Proximal Policy Optimization
Nikola Milosevic, Johannes Müller, Nico Scherf
The Exploration in AI Today Workshop at ICML 2025 2025
In constrained Markov decision processes, enforcing constraints during training is often thought of as decreasing the final return. Recently, it was shown that constraints can be incorporated directly in the policy geometry, yielding an optimization trajectory close to the central path of a barrier method, which does not compromise final return. Building on this idea, we introduce Central Path Proximal Policy Optimization (C3PO), a simple modification of PPO that produces policy iterates, which stay close to the central path of the constrained optimization problem. Compared to existing on-policy methods, C3PO delivers improved performance with tighter constraint enforcement, suggesting that central path-guided updates offer a promising direction for constrained policy optimization.
Open Problem: Active Representation Learning
Nikola Milosevic, Gesine Müller, Jan Huisken, Nico Scherf
ICML Workshop on Aligning Reinforcement Learning Experimentalists and Theorists (ARLET 2024) 2024
In this work, we introduce Active Representation Learning, a class of problems that intertwines exploration and representation learning within partially observable environments. We extend ideas from Active Simultaneous Localization and Mapping (active SLAM), and translate them to scientific discovery problems, exemplified by adaptive microscopy. We explore the need for a framework that derives exploration skills from representations, aiming to enhance the efficiency and effectiveness of data collection and model building in the natural sciences.
Open Problem: Active Representation Learning
Nikola Milosevic, Gesine Müller, Jan Huisken, Nico Scherf
ICML Workshop on Aligning Reinforcement Learning Experimentalists and Theorists (ARLET 2024) 2024
In this work, we introduce Active Representation Learning, a class of problems that intertwines exploration and representation learning within partially observable environments. We extend ideas from Active Simultaneous Localization and Mapping (active SLAM), and translate them to scientific discovery problems, exemplified by adaptive microscopy. We explore the need for a framework that derives exploration skills from representations, aiming to enhance the efficiency and effectiveness of data collection and model building in the natural sciences.